How can we learn high quality models when data is inherently distributed across sites and cannot be shared or pooled? In federated learning, the solution is to iteratively train models locally at each site and share these models with the server to be aggregated to a global model. As only models are shared, data usually remains undisclosed. This process, however, requires sufficient data to be available at each site in order for the locally trained models to achieve a minimum quality – even a single bad model can render aggregation arbitrarily bad.
In healthcare settings, however, we often have as little as a few dozens of samples per hospital. How can we still collaboratively train a model from a federation of hospitals, without infringing on patient privacy?

At this year’s ICLR, my colleagues Jonas Fischer, Jilles Vreeken and me presented an novel building block for federated learning called daisy-chaining. This approach trains models consecutively on local datasets, much like a daisy chain. Daisy-chaining alone, however, violates privacy, since a client can infer from a model upon the data of the client it received it from. Moreover, performing daisy-chaining naively would lead to overfitting which can cause learning to diverge. In our paper “Federated Learning from Small Datasets“, we propose to combine daisy-chaining of local datasets with aggregation of models, both orchestrated by the server, and term this method Federated Daisy-Chaining (FedDC).
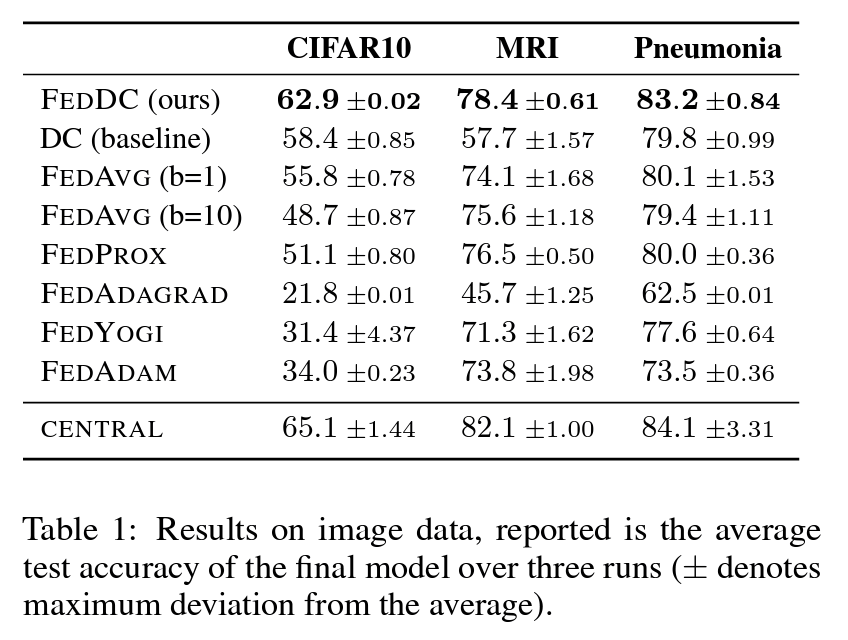
This approach allows us to train models successfully from as little as 2 samples per client. Our results on image data (Table 1) show that FedDC not only outperforms standard federated avering (FedAvg), but also state-of-the-art federated learning approaches, achieving a test accuracy close to centralized training.